
Introduction
Today, ChatGPT and tools like it, stand as a testament to AI’s capabilities, assisting in tasks from designing workout programs, to generating art, to writing code. Yet, for all its sophistication, interacting with ChatGPT can still feel distinctly non-human.
This sparked my curiosity about what it would take to make a “large language model” feel more humanlike. So I dove into the research and I’ve come to believe that there best practices already in use that could be adapted for this purpose.
Over the next six weeks, I will experiment with these approaches in an attempt to develop a chatbot with a personality that evolves through repeated interactions with users. Along the way, I will document my progress and setbacks weekly, while doing my best to explain these concepts with the least amount of technical jargon possible.
What are LLM’s
“LLM’s” or Large Language Models, are a subset, of a subset, of a subset of AI.
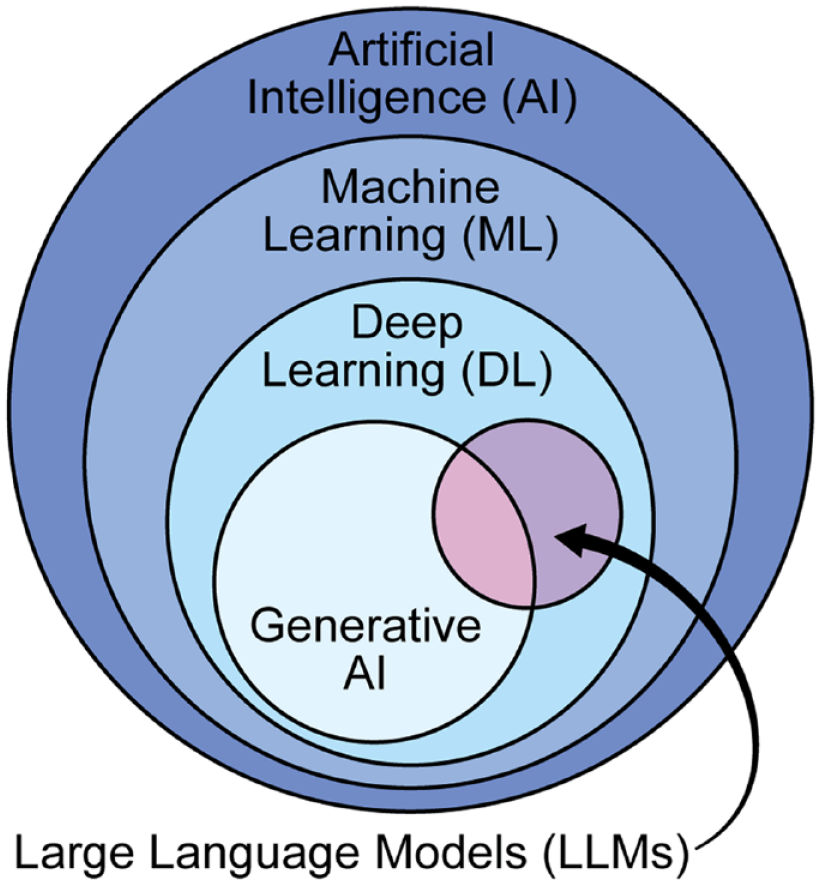
In deep learning, we “train” neural networks by giving them examples of the things we want them to learn. During this training process, we automatically “turn nobs” inside of the model until we get the desired output from the model.

The “Large” in LLM, refers to the fact that there are billions of tunable nobs within these models. In fact, the jump from GPT 1 to GPT 3 was over a 1,000x increase!

LLM’s use a special approach called “Attention“. In this context, it helps the model to naturally understand the importance of words relative to each other in a sentence.

Once the model is trained, we can “prompt” it with natural language, the way we would talk to a friend. It will run the prompt through its billions of specially set nobs, looking back at everything it has learned. Then it will generate a response by predicting the most likely next word, one at a time.

As a result, these models are really good at generating text, but can struggle with some types of logical reasoning, especially when faced with novel examples. The behavior of these models can be further steered through “prompt engineering” where we add additional context to help guide the type of text that is generated.

Existing Gaps
Despite all of this sophistication, anyone that has interacted with an LLM can tell you that it still doesn’t feel like you’re talking to a person. Even with a great “prompt engineering” you may get the model to exchange a couple dozen messages while staying in a character. (“Pretend you’re Dumbledore and chat with me like a friend…”). But eventually, it all falls apart.
To work on closing these gaps, I had to dig deeper and explicitly define some of the problems. I interacted with each of the major commercial models, some popular Chatbot Apps, and finally some of the open source LLM’s, and (qualitatively) evaluated performance across a few categories:
- Context: How long and how well it can remember things we discussed in previous conversations.
- Creativity: Does it come up with novel responses or does it begin to repeat itself.
- Character: How well can it get into a specific character if prompted and does the “personality” evolve naturally over the course of conversation.
Here are the models I “evaluated”:
Commercial Models: These are the largest, most powerful models on the market. But they are “closed source”, meaning that the companies do not give free access to the code or the “model weights”.
- GPT4
- Gemini 1.0 Pro
- Claude 3 Sonnet
Open Source: These are smaller models that can be run locally on a powerful enough computer. The developers behind these models freely share the code and the weights so you can download the models and improve them yourself.
- Llama 2 (7b) & 3 (8b)
- Mistral & Zephyr 7b
- Phi-3 Mini (128k)
Chatbot Apps: These are products designed to bring in money, so they are also closed source, but likely built on a specially crafted version of the open source models.
- Character AI
- Replika
At a high level, here were my findings:
- Context:
- All models could clearly recall information over multiple messages, but there was no “prioritization” of information. For example, they were just as likely to remember (or forget) my name as they were to remember the specific gym equipment that I have available at home.
Long term memory is a big limitation. After a certain number of messages are exchanged, information starts getting dropped.
- There are significant differences in what was retained from session to session, and across conversations.
- All models could clearly recall information over multiple messages, but there was no “prioritization” of information. For example, they were just as likely to remember (or forget) my name as they were to remember the specific gym equipment that I have available at home.
- Creativity:
- The models struggled to keep a novel conversation going, and eventually they often repeated themselves. It felt as though the “curiosity” was missing from the person on the other side. The smaller the model, the truer this was.
- The models struggled to keep a novel conversation going, and eventually they often repeated themselves. It felt as though the “curiosity” was missing from the person on the other side. The smaller the model, the truer this was.
- Character & Personality:
- All the large models demonstrated the ability to quickly jump “into character”, but not without warnings about how they were AI language models.
- However, none of them “evolved” over multiple interactions, showing a clear lack of long term “personality”.
- All the large models demonstrated the ability to quickly jump “into character”, but not without warnings about how they were AI language models.
Plan of Attack
With the gaps directionally identified, below is an outline of what I will attempt to implement over the coming weeks. Each week I’ll summarize my findings and explain what each of these approaches entail, with minimal technical jargon.
PART 1: Enhanced Short/Midterm memory: Optimize how much information is retained within a single conversation.
PART 2: Personality: Force the model to converge on a specific “personality” which can then evolve over time.
PART 3: Long Term Memory: Identify, store, and recall the most important details from conversations.
PART 4: Introspection: Allow continued “personality” evolution even in the absence of user prompts.
PART 5: Putting it all together: Put all the pieces together and deploy the model for 1 week and see what happens.
If you’re curious at all, feel free to follow along.
-Thaddeus

